Interarchive aims to change the paradigm of online scholarship by distributing the way research is published and cited across the entire Web. Although its initial focus is the media arts, Interarchive proposes an emergent approach to acquiring and recognizing influence that might be applied to any networked environment, whether the instruments of influence are academic papers or digital art.
Interarchive currently consists of two working groups:
Interarchive currently consists of two working groups:
- Interarchive general
-
This group focuses on a model for distributed publication, including the XML structure required for this paradigm.
- Recognition Metrics
-
This group focuses on devising innovative methods to visualize and assess the search returns resulting from the distributed publication paradigm.
Three Threats to the Survival of New Media
An online essay by Interarchive member Jon Ippolito on the mismatch between traditional approaches to preservation, property, and professorship. The discussion of "artists versus academics" lays out a number of the flaws inherent in the current system of academic recognition that Interarchive hopes to overcome. The site includes numerous links to examples and resources, including tools for creating Web pages for academics willing to wean themselves from PowerPoint.
Maine Intellectual Commons
An initiative by the University of Maine to establish open standards for creative and scholarly access. The site features archived audio, video, and slides from the November 2004 "Conference on the Intellectual Commons," which includes presentations on the value of open access publication and new models for supercharging online creativity via open licenses and networks.
New Standards for New Media
A collaborative Web site (wiki) that invites contributions from all stakeholders in the debate over academic criteria for recognizing new media research. The results are released under a Creative Commons license for re-editing and re-publication.
REFRESH! summit on media art databases
Notes from the archiving and database session of the REFRESH! post-conference summit.
An online essay by Interarchive member Jon Ippolito on the mismatch between traditional approaches to preservation, property, and professorship. The discussion of "artists versus academics" lays out a number of the flaws inherent in the current system of academic recognition that Interarchive hopes to overcome. The site includes numerous links to examples and resources, including tools for creating Web pages for academics willing to wean themselves from PowerPoint.
Maine Intellectual Commons
An initiative by the University of Maine to establish open standards for creative and scholarly access. The site features archived audio, video, and slides from the November 2004 "Conference on the Intellectual Commons," which includes presentations on the value of open access publication and new models for supercharging online creativity via open licenses and networks.
New Standards for New Media
A collaborative Web site (wiki) that invites contributions from all stakeholders in the debate over academic criteria for recognizing new media research. The results are released under a Creative Commons license for re-editing and re-publication.
REFRESH! summit on media art databases
Notes from the archiving and database session of the REFRESH! post-conference summit.
In the traditional academic publishing model, scholars compete for space in pricey print journals. In recent years online databases such as the Database of Virtual Art or Media Art Net have provided new venues for scholars to post research. Nevertheless, even open databases are not as accessible as they could be, for there currently exists no search engine that can search across these databases, nor is there an obvious way for individual creators and academics who aren't affiliated with these systems to contribute to them.
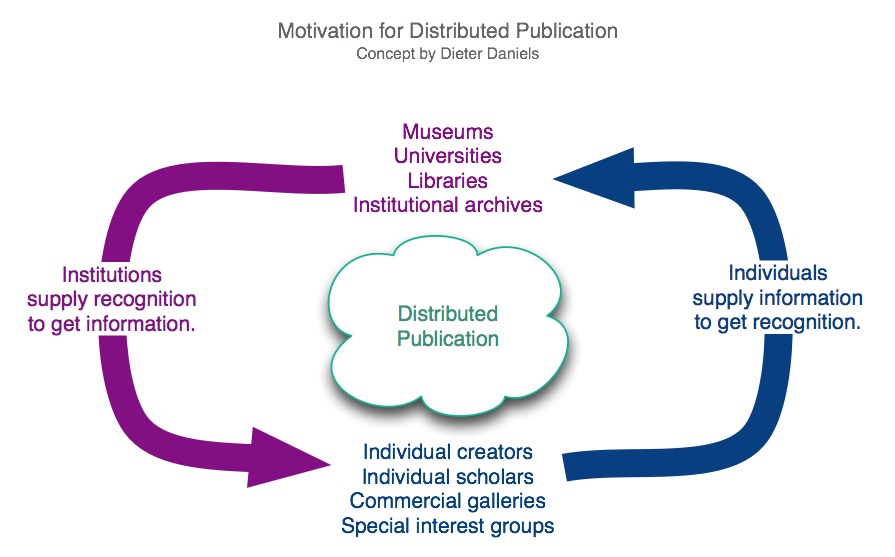
The Interarchive distributed publication working group is exploring an exciting paradigm that would let individual artists archive rich citations for their work on their own Web sites, and then those data could be harvested by museums and search engines after the fact. There aren't enough professional archivists to answer the growing need voiced by artists and writers in the new media community, so such a system would help distribute the work to those with the most incentive to do it. And it would be a "point-to-point" recognition metric, sidestepping middlemen like journals and museums--thus avoiding the positive feedback loop created when credibility comes from affiliation with an established institution.
This system would:
The Interarchive distributed publication working group is exploring an exciting paradigm that would let individual artists archive rich citations for their work on their own Web sites, and then those data could be harvested by museums and search engines after the fact. There aren't enough professional archivists to answer the growing need voiced by artists and writers in the new media community, so such a system would help distribute the work to those with the most incentive to do it. And it would be a "point-to-point" recognition metric, sidestepping middlemen like journals and museums--thus avoiding the positive feedback loop created when credibility comes from affiliation with an established institution.
This system would:
- Scale with the number of users.
- Distribute the workload to those with the most incentive.
- Result in productive redundancy between self-archived citations and copies in open repositories.
- Permit multiple metrics developed by third parties.
- Encourage metrics to be emergent from the community rather than imposed in a top-down fashion.
There are numerous possible implementations of the distributed publication paradigm, but one possible model is based on the XML license encoding currently used by Creative Commons to help its users embed licenses in Web pages or search for open licensed work.
The artists, musicians, and writers who navigate through Creative Commons' "choose a license" interface are rewarded with a pretty icon and a snippet of XML they can paste into their own Web page. Meanwhile, in the background, an automated harvester indexes occurrences of the Creative-Commons flavor of XML on Web pages throughout the Internet. Finally, someone who wants to find Creative Commons-licensed material can use the Creative Commons search engine (now Yahoo) to find any of these pages that match a certain criterion.
The distributed publication scheme is an extrapolation of this technology, but instead of a choose-your-license interface, this system might generate and harvest "rich links"--that is, citations of online art or scholarship with more metadata than your average hyperlink. Such metadata might address content (eg, via a folksonomy) and/or value (eg, by rating the link 1 to 10). For example, you might score low an article or artwork you are citing merely to review the literature, but highly a work you are citing because all of your research is based on that precedent. The links might refer to specialized data relations (such as the link between an artwork and the corresponding entry in the variable media database) or more generic associations (one artwork could link to another as precedent).
The link generator interface would facilitate the embedding of these rich links in online publications (perhaps by adding metadata to a link via a bookmarklet). The real benefit would become visible (quite literally) through a variety of recognition metrics that can be applied to the search returns. Proposing these metrics is the job of the job of the Recognition Metrics group.
The artists, musicians, and writers who navigate through Creative Commons' "choose a license" interface are rewarded with a pretty icon and a snippet of XML they can paste into their own Web page. Meanwhile, in the background, an automated harvester indexes occurrences of the Creative-Commons flavor of XML on Web pages throughout the Internet. Finally, someone who wants to find Creative Commons-licensed material can use the Creative Commons search engine (now Yahoo) to find any of these pages that match a certain criterion.
The distributed publication scheme is an extrapolation of this technology, but instead of a choose-your-license interface, this system might generate and harvest "rich links"--that is, citations of online art or scholarship with more metadata than your average hyperlink. Such metadata might address content (eg, via a folksonomy) and/or value (eg, by rating the link 1 to 10). For example, you might score low an article or artwork you are citing merely to review the literature, but highly a work you are citing because all of your research is based on that precedent. The links might refer to specialized data relations (such as the link between an artwork and the corresponding entry in the variable media database) or more generic associations (one artwork could link to another as precedent).
The link generator interface would facilitate the embedding of these rich links in online publications (perhaps by adding metadata to a link via a bookmarklet). The real benefit would become visible (quite literally) through a variety of recognition metrics that can be applied to the search returns. Proposing these metrics is the job of the job of the Recognition Metrics group.
Citation generation and harvesting
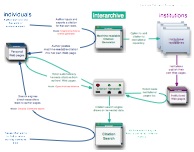
This diagram shows the cycle of auto-archiving, harvesting, and searching, as well as the interrelation of individual users and official archivists.
Motivation
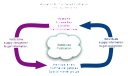
This diagram suggests the incentives driving the Interarchive cycle.
This diagram shows the cycle of auto-archiving, harvesting, and searching, as well as the interrelation of individual users and official archivists.
Motivation
This diagram suggests the incentives driving the Interarchive cycle.
{kind=link}
Recent news from the Interarchive blog appears at right; you can visit the blog directly at http://interarchive.blogspot.com.
The measures of recognition currently employed by academia discount the increasing influence the Web wields on all forms of scholarship, but especially scholarship on new media and their effects. Academic search and tenure committees are accustomed to evaluating candidates based on limited numerical summaries such as the number of print articles and the exclusivity of the journals in which they are published. Yet such restricted measures of peer influence seem increasingly outdated in an information economy that values accessibility over exclusivity, where published research need no longer be restricted to printed articles but may find more influential outlets in Web-based journals, blogs, online data stores, or open software repositories.
The Recognition Metric working group is charged with proposing more nuanced measures of online influence. This can be seen as adding the last piece to the Distributed Publication puzzle: how are search returns configured in response to a researcher's query? Can we use the data from a distributed publication scheme to draw contextual "influence clouds" that visualize the vectors of influence online better than a list of names with numbers next to them?
The Recognition Metric working group is charged with proposing more nuanced measures of online influence. This can be seen as adding the last piece to the Distributed Publication puzzle: how are search returns configured in response to a researcher's query? Can we use the data from a distributed publication scheme to draw contextual "influence clouds" that visualize the vectors of influence online better than a list of names with numbers next to them?
This group is interested in drawing clouds of influence in addition to or instead of ranks. Unlike the academic ranks commonly applied to assess research impact, such clouds of impact could be:
- contextual (relative to the subculture being measured).
- multiple (applicable to more than one subculture).
- variable (reflecting changes over shorter timescales than a global metric).
- net-native (emergent from the Internet rather than predetermined by affiliations with brick-and-mortar institutions).
Recent news from the Recognition-Metrics blog appears at right; you can visit the blog directly at http://recognitionmetrics.blogspot.com.
Individuals confirmed
- Alain Depocas
- Jon Ippolito
- Caitlin Jones
- Roger Malina
- Richard Rinehart
- Christian Berndt
- Sylvia Borda
- Annick Bureaud
- Wendy Coones
- Sean Cubitt
- Marcus Cuzziol
- Dieter Daniels
- Rudolf Frieling
- Oliver Grau
- Genco Gulan
- Ryszard Kluszcynski
- Gunalan Nadarajan
- Minna Tarkka
Organizations confirmed
- Daniel Langlois Foundation for Art, Science, and Technology
- Database of Virtual Art
- Media Art Net
- MIT Press
- Still Water at the University of Maine
- UC Berkeley Center for New Media
To join the Interarchive email list, send an email to ude.yelekreb.stsil@omodrojaM with the message, "subscribe interarchive YourEmailAddressHere". After subscribing, post email to this list at: ude.yelekreb.stsil@evihcraretni.
To join the Recognition Metrics email list, send an email to ude.yelekreb.stsil@omodrojaM with the message, "subscribe recognition-metrics YourEmailAddressHere". After subscribing, post email to this list at: ude.yelekreb.stsil@scirtem-noitingocer.
To leave either list, follow the instructions above, but change "subscribe" to "unsubscribe".
To join the Recognition Metrics email list, send an email to ude.yelekreb.stsil@omodrojaM with the message, "subscribe recognition-metrics YourEmailAddressHere". After subscribing, post email to this list at: ude.yelekreb.stsil@scirtem-noitingocer.
To leave either list, follow the instructions above, but change "subscribe" to "unsubscribe".
Warning: require_once(/Library/WebServer/Documents/NMsite/newmedia/php/magpie/rss_fetch.inc) [function.require-once]: failed to open stream: No such file or directory in /var/www/html/NM/NMSite/newmedia/interarchive/home.php on line 274
Fatal error: require_once() [function.require]: Failed opening required '/Library/WebServer/Documents/NMsite/newmedia/php/magpie/rss_fetch.inc' (include_path='.:/usr/share/pear:/usr/share/php:/Library/WebServer/Documents/NMsite/newmedia/php/db/:/Library/WebServer/Documents/NMsite/newmedia/php/smarty/:/Library/WebServer/Documents/NMsite/newmedia/php/:/Library/WebServer/Documents/NMsite/newmedia/templates_c/') in /var/www/html/NM/NMSite/newmedia/interarchive/home.php on line 274